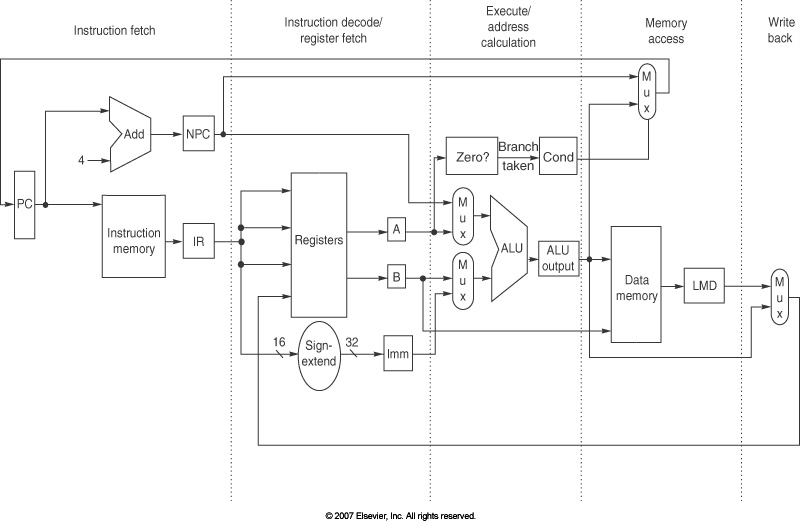
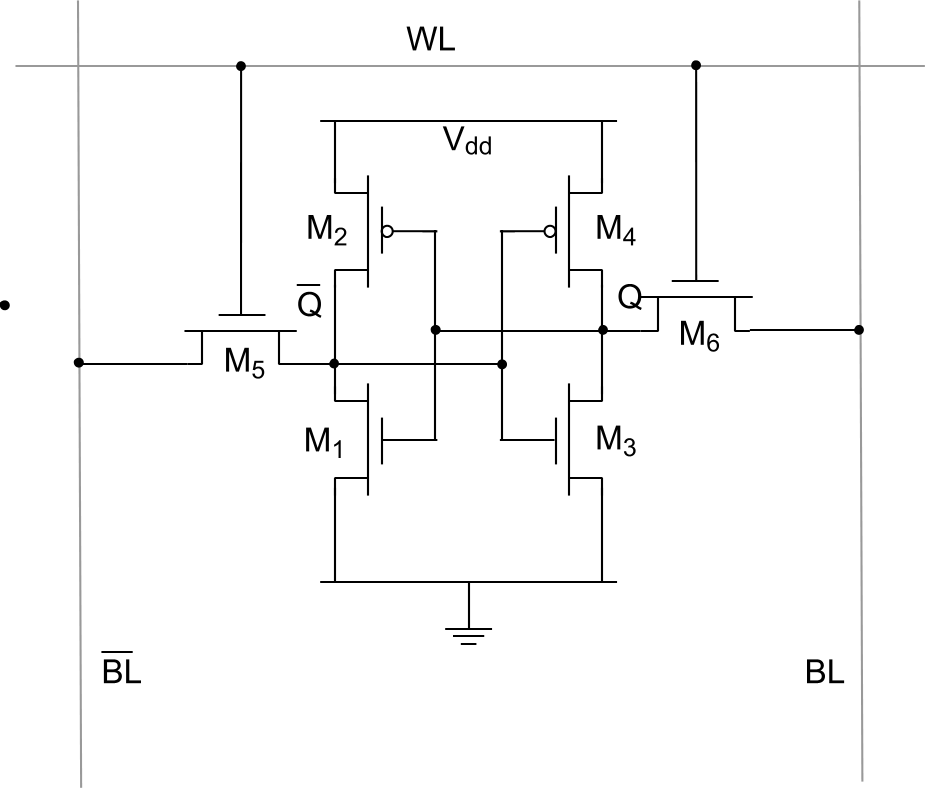
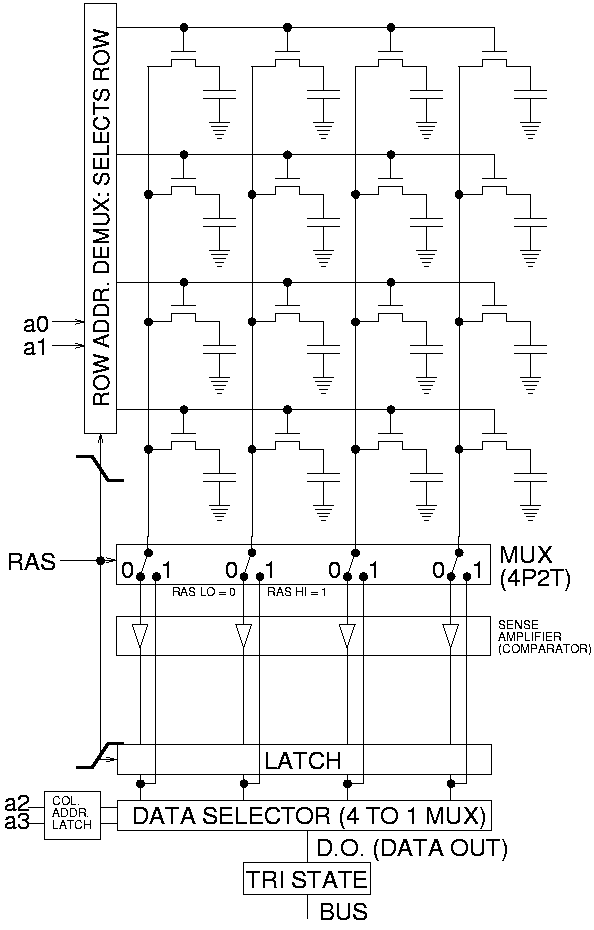
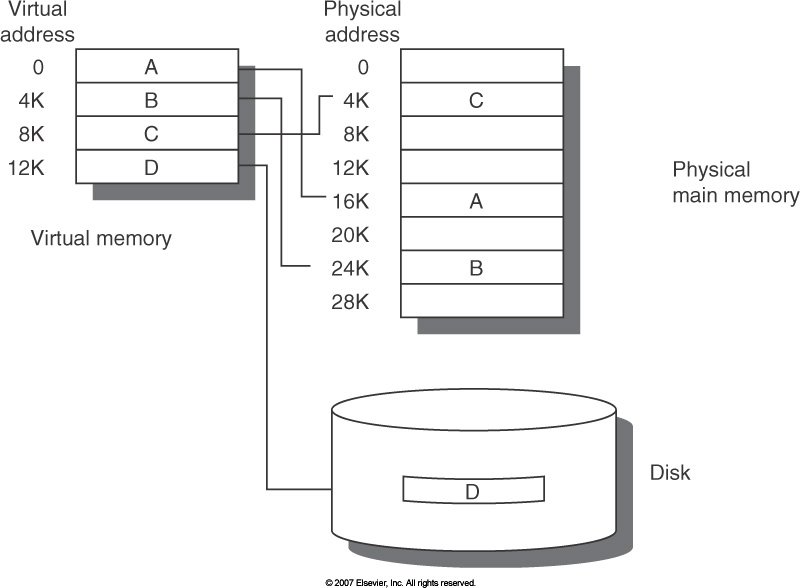
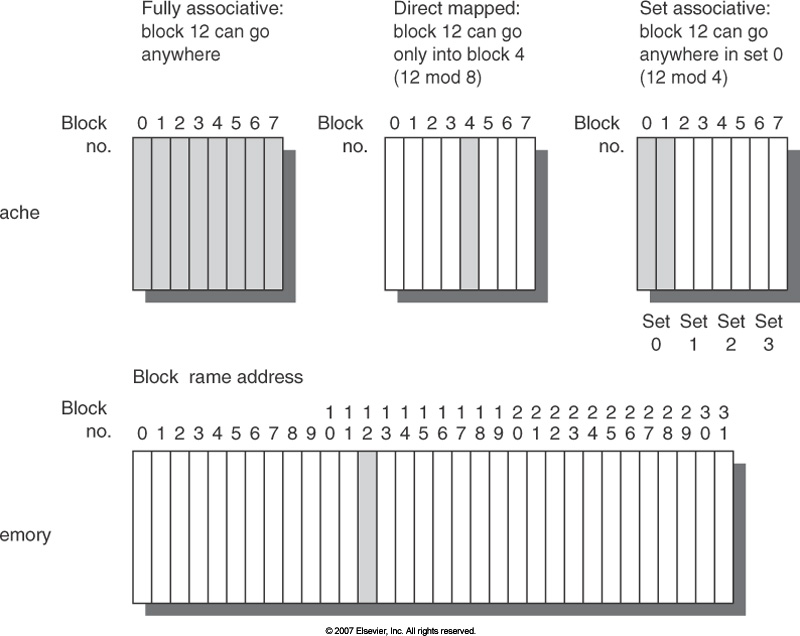
In hardware, caches are usually organized as direct mapped, set associative, or fully associative.
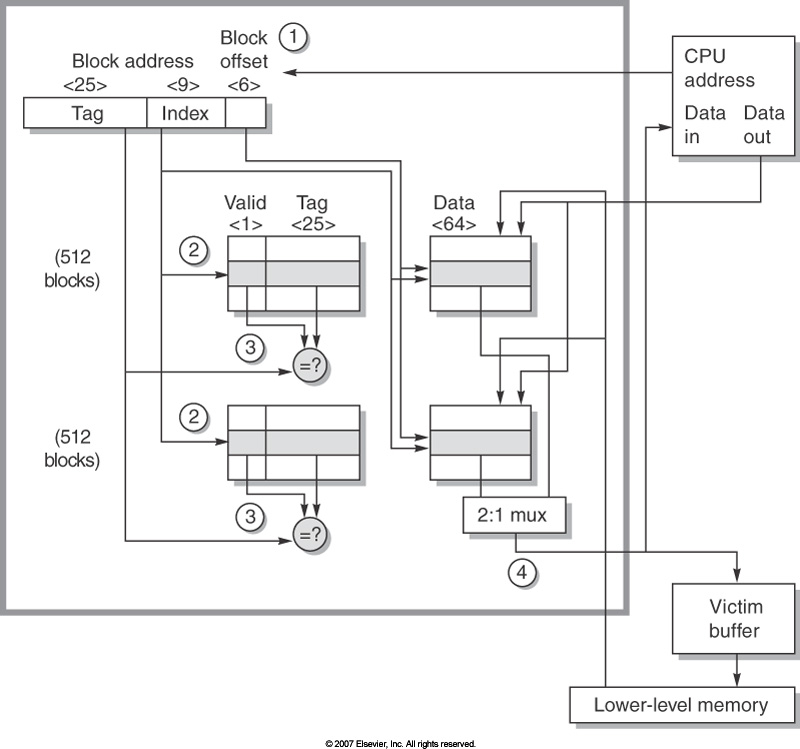
Generally, an address is divided into the block address and the block offset. The block address is further divided into the tag and the index.

The AMD Opteron processor uses a 64KB cache, two-way set associative, 64 byte blocks. Addresses are 40 bit physical addresses. In the figure below, you can see the physical address in the upper left hand corner.
- The upper (high-order, or left-most) 25 bits of the address are the tag,
- the next (middle) 9 bits are the index, and
- the low-order 6 bits are the block offset.
- Random
- Least-recently used (LRU)
- First in, first out (FIFO)
- Write through
- Write back
- Write allocate or no-write allocate?