Management of errors in data, including their detection, and, when possible, correction, is critical to the correct operation of real-world computer systems, as well as being one of the most profound theoretical advances in the last century or so. If there is only one copy of a particular piece of data, and that copy is destroyed, there is no recourse: the data is gone. Simply put, then, error correction must expand the data in order to protect it.
The simplest form of error correction is to replicate the data several times (e.g., in what we call triple redundancy):0 --> 000 1 --> 111
Then, when a error occurs, such as a bit flip, we can see the effect:
000 --> 010 111 --> 101
Intuitively, we can look at the string 010 and think, "Oh, the value should have been a zero," and correct the error. The math gets a lot more formal, but that's the basic idea.
This area is broad enough and deep enough that there are textbooks, courses, and conferences on the topic; obviously, we are not going into much depth here. But we would like to know about the impact of errors on systems, so we need a few basic concepts:
Ah, finally, we come to RAID: Redundant Array of Independent Disks. RAID began developing much earlier, but the term itself and the beginnings of the formalization of RAID theory were developed in the mid-1980s at U.C. Berkeley, by David Patterson, Garth Gibson, Randy Katz, and others, and appeared in a seminal 1988 paper. They asserted that RAID systems can use multiple disks to store one data set and achieve large gains in performance, reliability, power consumption, and scalability.
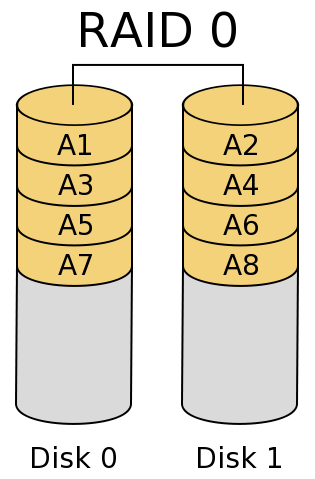
Simply striping across multiple disks can improve capacity, bandwidth and transactions/second. However it provides no protection for the data, and indeed, the probability of a failure among several disks is higher than one disk.
Simply mirroring across multiple disks can improve bandwidth for large reads (but not small ones) and read operations/second (but not writes!) (Why?).
What failures can mirroring protect against? Above, we indicated that it takes at least three copies of the data to protect against an unlocated error. The picture shows only two. Why?
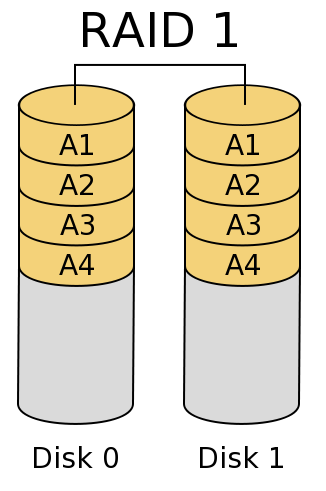
Disk failures are (generally) located. That is, when a disk crashes, we usually know! Therefore, if we know that the left hand disk has died, we know we can replace it and simply copy the data back from the right hand drive.
Mirroring is wasteful: it uses twice as much disk space as the data itself. If we spread the data across more than two disks, we can use use erasure correction techniques to determine if an error occurs, and the parity of the data will allow us to recreate the missing data!
In a RAID 3 architecture, a single, large data block is spread out across multiple drives, and the parity of the constituent blocks is calculated and stored in the parity drive.
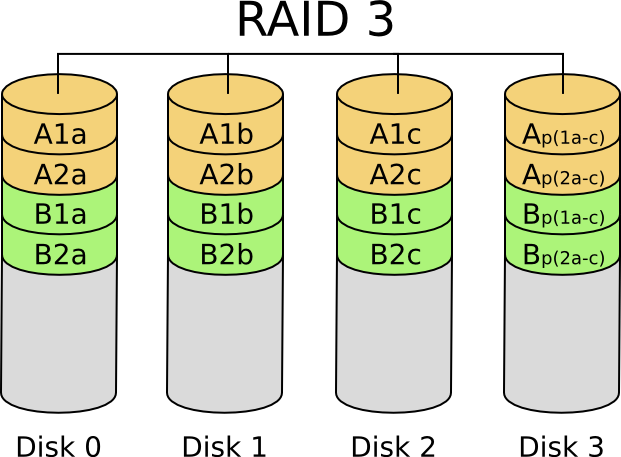
RAID-3 is good for large reads and writes. It is not good for small operations, because e.g. reading block A1 in the picture requires reading from all three drives.
Because every data block is striped across multiple disks, every RAID 3 operation touches all of the disks on write, and all but the parity disk on read. By doing block level striping instead, a whole block is stored on one drive, and each disk can operate independently much of the time. With N data disks, RAID 4 can perform N block reads in parallel. However, every write must update the parity disk, so write performance is limited to the performance of one drive.
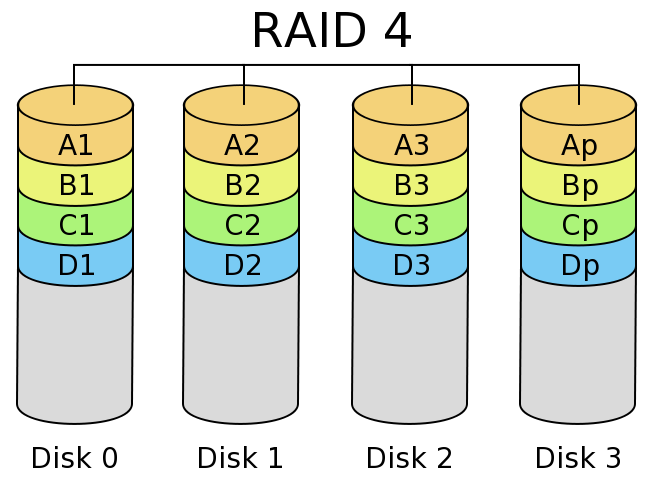
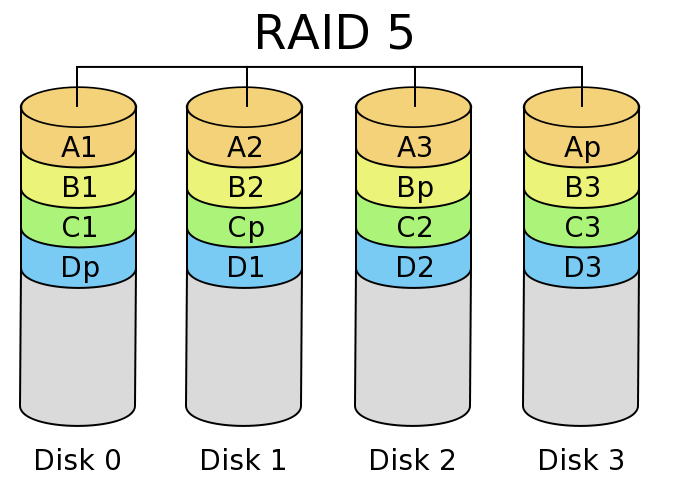
In write-heavy workloads (including reconstruction of a failed drive), the parity disk in RAID 4 is usually the bottleneck. In RAID 5, the parity rotates among the drives, allowing updates to done in parallel. Write performance is still only about N/3 for N disks, but it's a lot more scalable than RAID 4. Read performance is also slightly higher.
One critical feature of a computer system is its ability to do many things at once: there may be more than one CPU, each of which may have its own cache memory, and disk drives, network adapters, and other hardware units may all be operating independently and concurrently. Often, it is necessary to synchronize operations among the units; there are many hardware and software mechanisms for performing synchronization, which we haven't had time to study. However, the concept is critical.
What happens when two processors try to update a memory location at the same time?