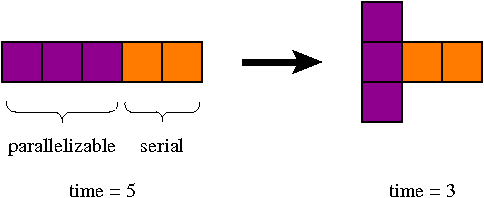
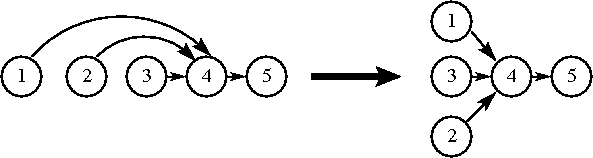
The parallelism achievable is determined by the dependency graph. Creating that graph and scheduling operations to maximize the parallelism and enforce correctness is generally the shared responsibility of the hardware architecture and the compiler.
Let's look at it mathematically:
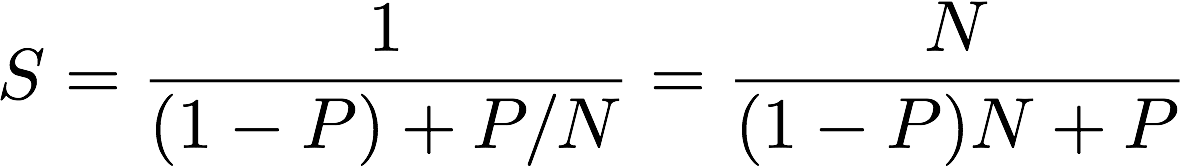
Question: What is the limit of this as N goes to infinity?
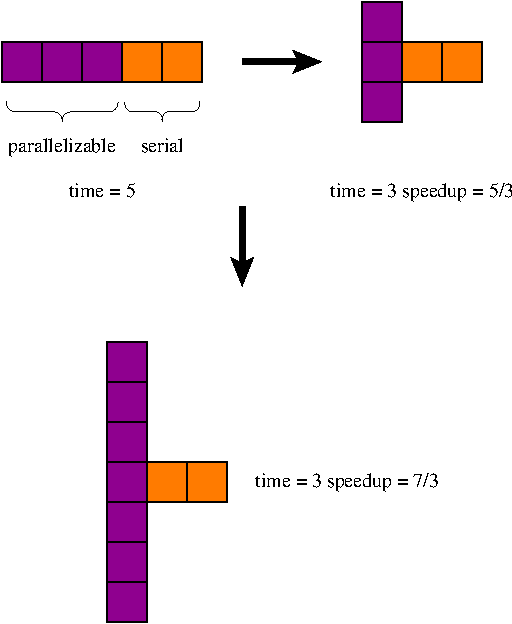
See the description of Amdahl's Law on Wikipedia.
Amdahl's Law can also be applied to serial problems. An example adapted from Wikipedia:
If your car is traveling 50km/h, and you want to travel 100km, how long will it take?
After one hour, your car speeds up to 100km/h. What is your average speed? If your car becomes infinitely fast, what is the average speed? More importantly, what's the minimum time for the complete trip?
Now go back to the example above. In practice, when your car gets faster, it becomes possible for you to go farther.
For the first hour, your car runs at 50km/h. After one hour, your car speeds up to 100km/h. What's the limit of your average speed if you lengthen your trip?
Gustafson's Law (or the Gustafson-Barsis Law) basically says that parallelism gives you the freedom to make your problem bigger. 25 years ago, we thought that 100,000 processors or 1,000,000 processors was ridiculous, because Amdahl's Law limited their use. Today, systems in that size range are increasingly common, and it's because of Gustafson-Barsis.
See Gustafson's Law on Wikipedia.
The fundamental observation is this:
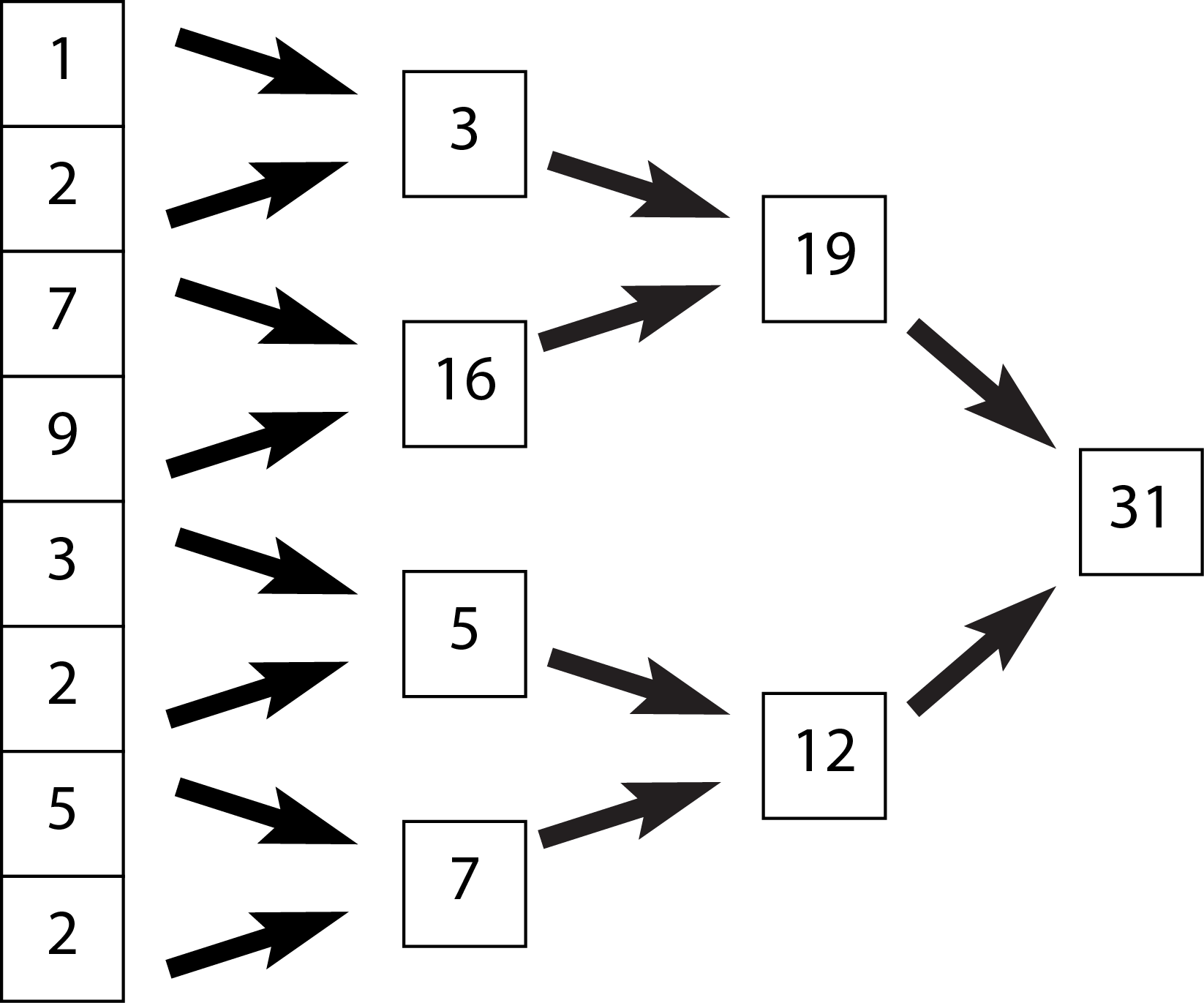
In OpenMP, this can be achieved via something like
#pragma omp parallel for reduction(+:result)
for ( i = 0 ; i < n ; i++ ) {
result += array[i];
}