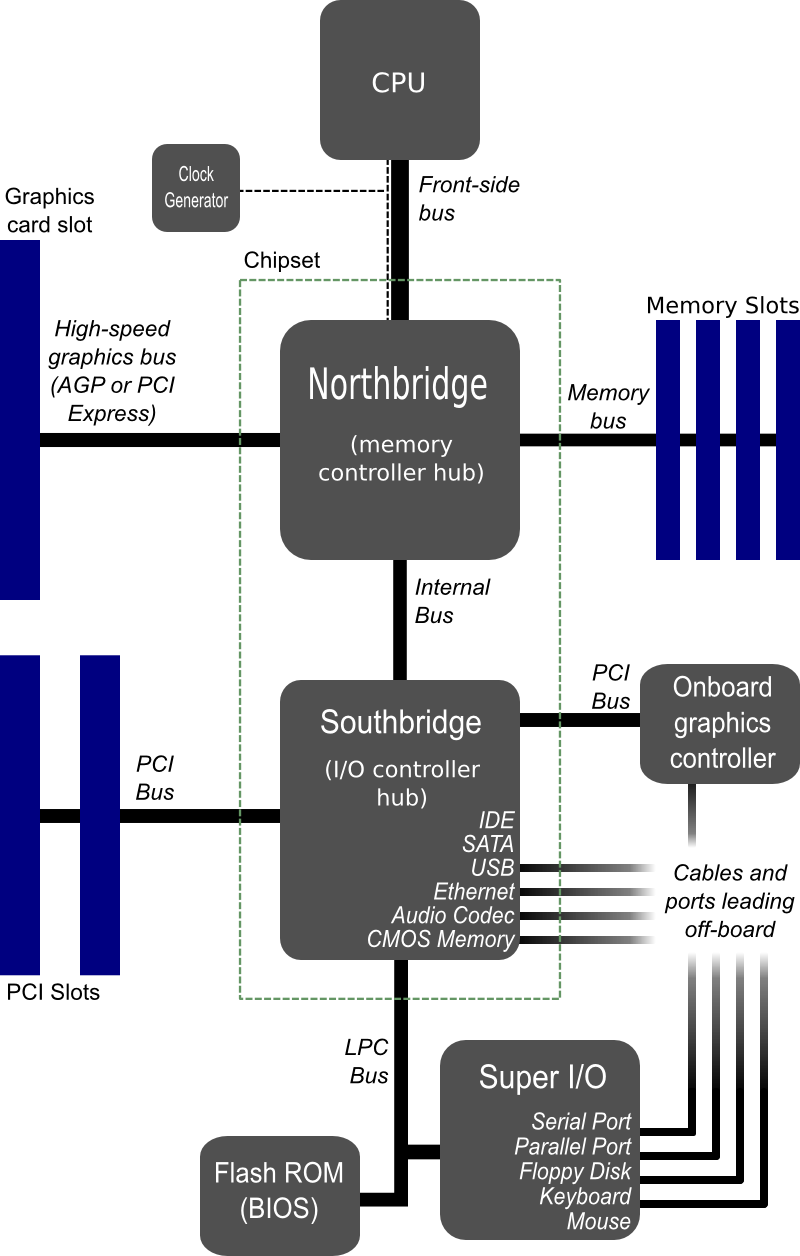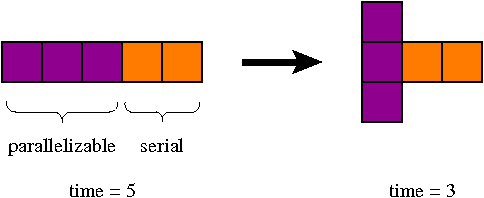
Last week, we discussed some performance graphs, plotting (a) wall-clock time, (b) speedup, and (c) efficiency versus the number of threads used on a particular problem. This week, each of you will see how to take that data, and how to recreate the graphs. You need R, an account on a Unix-like machine with more than one core and an OpenMP-capable compiler, and the code available from the link below at Homework.
Note on compilers: On the Mac, Apple's supplied compiler is called gcc, but it is really the Clang compiler, not the true GNU gcc. That would be fine, since it's mostly compatible, but there are some features of one not present in the other. In particular, for this exercise you will need the parallel extensions for C known as OpenMP, and Clang does not provide them. And, of course, on a Windows box, your compiler will likely be different. So, we recommend using the Docker that Nikko created, which has the right tools. Alternatively, you can do one of four other things to get access to a real gcc: a) use ccx, the servers provided by campus; b) use your own Linux or FreeBSD box, or one from your lab; c) install gcc5 (or gcc4) for Mac on your machine, or d) install a Vagrant VirtualBox. I have done all of the above. If you want to use gcc-5 on your Mac, remember to change the first line in both Makefiles to:
CC=gcc-5
That should allow you to compile the OpenMP program properly.
#define LOOP 1000 #define REGISTER_SIZE 20Edit the file and fix those parameters, if they are different.
1 440 435 0.2 2 229 451 0.36 3 161 475 0.42 4 122 482 0.4
> ARMDATA1 <- matrix(scan("armstrong-one-run.dat"),ncol=4,byrow=T)
Read 48 items
> plot(ARMDATA1[,1],ARMDATA1[,2])
> x <- seq(1,16)
> y = 440/x
> points(x,y,type="l")
> help(plot)
> plot(ARMDATA1[,1],ARMDATA1[,2],log="y")
> points(x,y,type="l")
> plot(ARMDATA1[,1],ARMDATA1[,2],log="xy")
> points(x,y,type="l")
Here is my log from creating a vagrant machine on my laptop on 2019/6/8. It took about ten minutes for the hashicorp to download and install properly, after I already had vagrant installed and had previously used it.
Van-Meter-Rodneys-MacBook-Pro:computer-architecture-2019 rdv$ vagrant init hashicorp/precise64
A `Vagrantfile` has been placed in this directory. You are now
ready to `vagrant up` your first virtual environment! Please read
the comments in the Vagrantfile as well as documentation on
`vagrantup.com` for more information on using Vagrant.
Van-Meter-Rodneys-MacBook-Pro:computer-architecture-2019 rdv$ vagrant up
Bringing machine 'default' up with 'virtualbox' provider...
==> default: Box 'hashicorp/precise64' could not be found. Attempting to find and install...
default: Box Provider: virtualbox
default: Box Version: >= 0
==> default: Loading metadata for box 'hashicorp/precise64'
default: URL: https://vagrantcloud.com/hashicorp/precise64
==> default: Adding box 'hashicorp/precise64' (v1.1.0) for provider: virtualbox
default: Downloading: https://atlas.hashicorp.com/hashicorp/boxes/precise64/versions/1.1.0/providers/virtualbox.box
==> default: Successfully added box 'hashicorp/precise64' (v1.1.0) for 'virtualbox'!
==> default: Importing base box 'hashicorp/precise64'...
==> default: Matching MAC address for NAT networking...
==> default: Checking if box 'hashicorp/precise64' is up to date...
==> default: Setting the name of the VM: computer-architecture-2019_default_1465374178790_32575
==> default: Clearing any previously set network interfaces...
==> default: Preparing network interfaces based on configuration...
default: Adapter 1: nat
==> default: Forwarding ports...
default: 22 => 2222 (adapter 1)
==> default: Booting VM...
==> default: Waiting for machine to boot. This may take a few minutes...
default: SSH address: 127.0.0.1:2222
default: SSH username: vagrant
default: SSH auth method: private key
default: Warning: Remote connection disconnect. Retrying...
==> default: Machine booted and ready!
==> default: Checking for guest additions in VM...
default: The guest additions on this VM do not match the installed version of
default: VirtualBox! In most cases this is fine, but in rare cases it can
default: prevent things such as shared folders from working properly. If you see
default: shared folder errors, please make sure the guest additions within the
default: virtual machine match the version of VirtualBox you have installed on
default: your host and reload your VM.
default:
default: Guest Additions Version: 4.2.0
default: VirtualBox Version: 4.3
==> default: Mounting shared folders...
default: /vagrant => /Users/rdv/old/rdv/keio/sfc/teaching/rdvteachingweb/computer-architecture/computer-architecture-2019
Here is some data I took in fall 2015:
Van-Meter-Rodneys-MacBook-Pro:vagrant-files rdv$ vagrant up
Bringing machine 'default' up with 'virtualbox' provider...
==> default: Clearing any previously set forwarded ports...
==> default: Clearing any previously set network interfaces...
==> default: Preparing network interfaces based on configuration...
default: Adapter 1: nat
==> default: Forwarding ports...
default: 22 => 2222 (adapter 1)
==> default: Running 'pre-boot' VM customizations...
==> default: Booting VM...
==> default: Waiting for machine to boot. This may take a few minutes...
default: SSH address: 127.0.0.1:2222
default: SSH username: vagrant
default: SSH auth method: private key
default: Warning: Connection timeout. Retrying...
default: Warning: Remote connection disconnect. Retrying...
==> default: Machine booted and ready!
==> default: Checking for guest additions in VM...
==> default: Mounting shared folders...
default: /vagrant => /Users/rdv/new/quantum/vagrant-files
==> default: Machine already provisioned. Run `vagrant provision` or use the `--provision`
==> default: to force provisioning. Provisioners marked to run always will still run.
Van-Meter-Rodneys-MacBook-Pro:vagrant-files rdv$ vagrant ssh
Last login: Mon Oct 5 00:17:27 2015 from 10.0.2.2
-bash: warning: setlocale: LC_CTYPE: cannot change locale (UTF-8): No such file or directory
[vagrant@localhost ~]$ more /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 70
model name : Intel(R) Core(TM) i7-4750HQ CPU @ 2.00GHz
stepping : 1
cpu MHz : 1997.136
cache size : 6144 KB
physical id : 0
siblings : 4
core id : 0
cpu cores : 4
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 5
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pa
t pse36 clflush mmx fxsr sse sse2 ht syscall nx rdtscp lm constant_tsc rep_good pn
i ssse3 lahf_lm
bogomips : 3994.27
clflush size : 64
cache_alignment : 64
address sizes : 39 bits physical, 48 bits virtual
power management:
processor : 1
vendor_id : GenuineIntel
cpu family : 6
model : 70
model name : Intel(R) Core(TM) i7-4750HQ CPU @ 2.00GHz
stepping : 1
cpu MHz : 1997.136
cache size : 6144 KB
physical id : 0
siblings : 4
core id : 1
cpu cores : 4
apicid : 1
initial apicid : 1
fpu : yes
fpu_exception : yes
cpuid level : 5
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pa
t pse36 clflush mmx fxsr sse sse2 ht syscall nx rdtscp lm constant_tsc rep_good pn
i ssse3 lahf_lm
bogomips : 3994.27
clflush size : 64
cache_alignment : 64
address sizes : 39 bits physical, 48 bits virtual
power management:
processor : 2
vendor_id : GenuineIntel
cpu family : 6
model : 70
model name : Intel(R) Core(TM) i7-4750HQ CPU @ 2.00GHz
stepping : 1
cpu MHz : 1997.136
cache size : 6144 KB
physical id : 0
siblings : 4
core id : 2
cpu cores : 4
apicid : 2
initial apicid : 2
fpu : yes
fpu_exception : yes
cpuid level : 5
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pa
t pse36 clflush mmx fxsr sse sse2 ht syscall nx rdtscp lm constant_tsc rep_good pn
i ssse3 lahf_lm
bogomips : 3994.27
clflush size : 64
cache_alignment : 64
address sizes : 39 bits physical, 48 bits virtual
power management:
processor : 3
vendor_id : GenuineIntel
cpu family : 6
model : 70
model name : Intel(R) Core(TM) i7-4750HQ CPU @ 2.00GHz
stepping : 1
cpu MHz : 1997.136
cache size : 6144 KB
physical id : 0
siblings : 4
core id : 3
cpu cores : 4
apicid : 3
initial apicid : 3
fpu : yes
fpu_exception : yes
cpuid level : 5
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pa
t pse36 clflush mmx fxsr sse sse2 ht syscall nx rdtscp lm constant_tsc rep_good pn
i ssse3 lahf_lm
bogomips : 3994.27
clflush size : 64
cache_alignment : 64
address sizes : 39 bits physical, 48 bits virtual
power management:
[vagrant@localhost ~]$
[vagrant@localhost ~]$ cd architecture/
[vagrant@localhost architecture]$ ls
architecture-hw1-111007.tgz data src
[vagrant@localhost architecture]$ cd src
[vagrant@localhost src]$ ls
AAAREADME.txt hw1 qulib
[vagrant@localhost src]$ cd hw1/
[vagrant@localhost hw1]$ ls
Makefile hw1 main.c main.o
[vagrant@localhost hw1]$ time ./hw1
real 0m7.044s
user 0m27.129s
sys 0m1.013s
[vagrant@localhost hw1]$ export OMP_NUM_THREADS=1
[vagrant@localhost hw1]$ time ./hw1
real 0m10.428s
user 0m10.386s
sys 0m0.038s
[vagrant@localhost hw1]$ export OMP_NUM_THREADS=2
[vagrant@localhost hw1]$ time ./hw1
real 0m7.412s
user 0m14.370s
sys 0m0.447s
[vagrant@localhost hw1]$ export OMP_NUM_THREADS=3
[vagrant@localhost hw1]$ time ./hw1
real 0m6.995s
user 0m20.348s
sys 0m0.625s
[vagrant@localhost hw1]$ export OMP_NUM_THREADS=4
[vagrant@localhost hw1]$ time ./hw1
real 0m6.860s
user 0m26.468s
sys 0m0.943s
[vagrant@localhost hw1]$ export OMP_NUM_THREADS=5
[vagrant@localhost hw1]$ time ./hw1
real 0m7.361s
user 0m21.475s
sys 0m1.526s
[vagrant@localhost hw1]$ export OMP_NUM_THREADS=6
[vagrant@localhost hw1]$ time ./hw1
real 0m7.391s
user 0m21.657s
sys 0m1.494s
[vagrant@localhost hw1]$ export OMP_NUM_THREADS=8
[vagrant@localhost hw1]$ time ./hw1
real 0m6.954s
user 0m20.681s
sys 0m1.600s
[vagrant@localhost hw1]$ export OMP_NUM_THREADS=16
[vagrant@localhost hw1]$ time ./hw1
real 0m6.762s
user 0m20.034s
sys 0m2.429s
[vagrant@localhost hw1]$
I ran this on a Vagrant VirtualBox running CentOS on my Mac. You can see that the performance improvement was only modest. Why do you think that is?
Let's talk about Hennessy & Patterson's Five Principles:
| CPU time = | (seconds )/ program | = | (Instructions )/ program | × | (Clock cycles )/ Instruction | × | (Seconds )/ Clock cycle |
(Here's the fun part...)