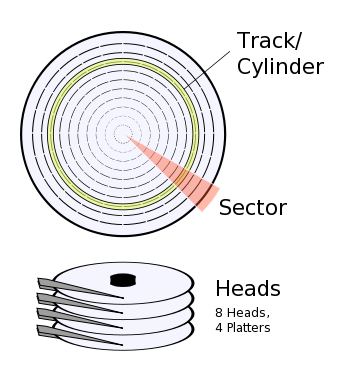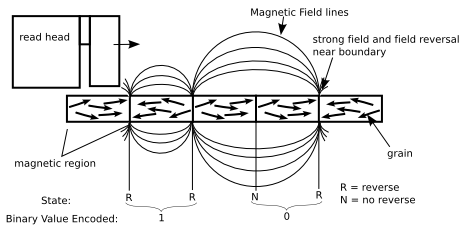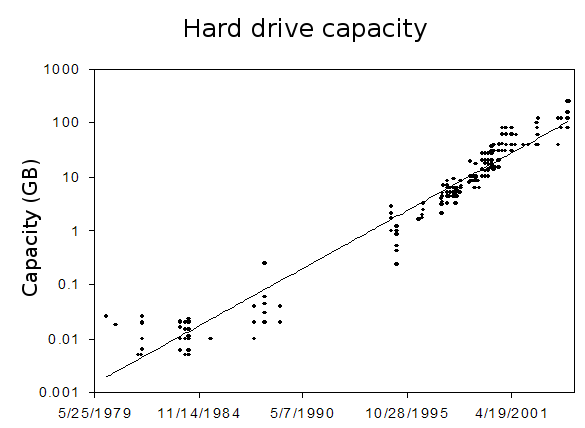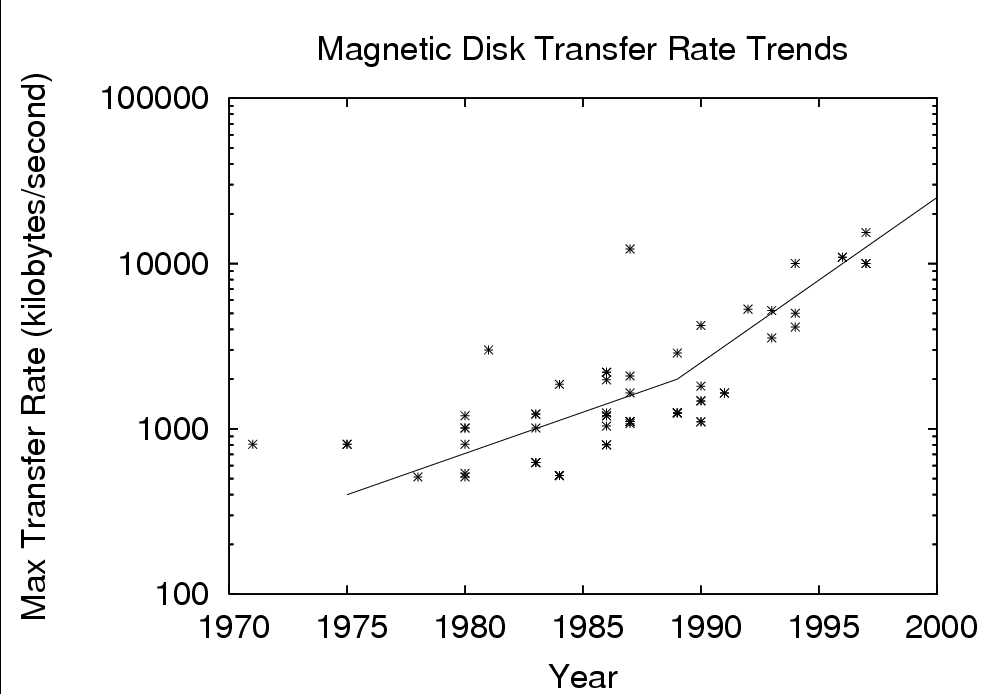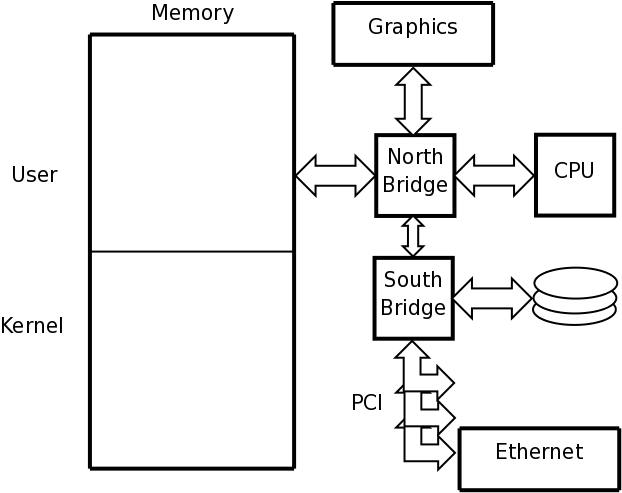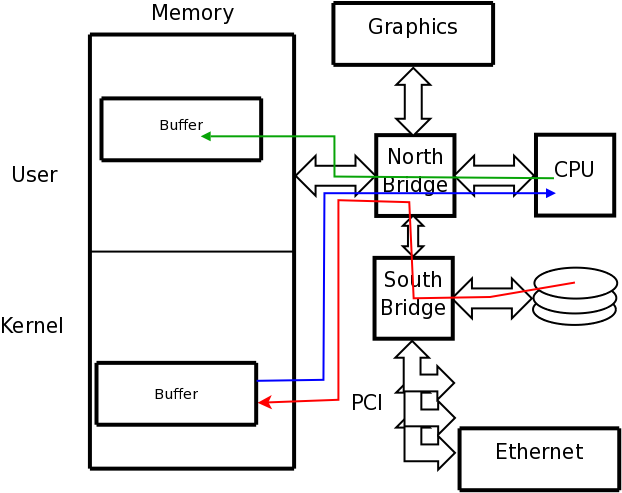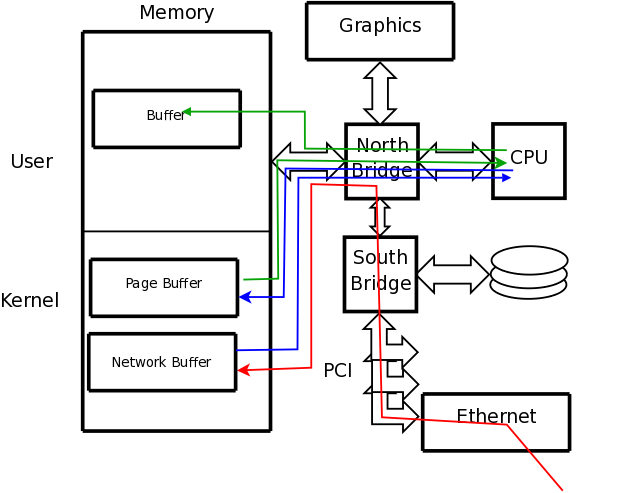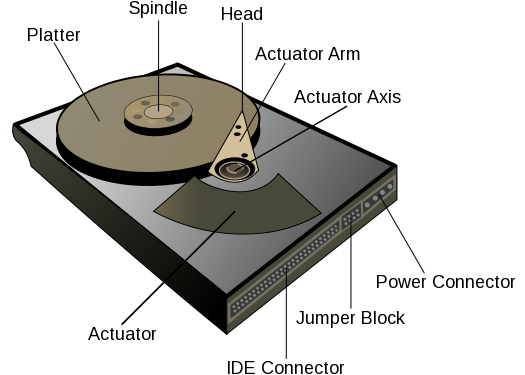
A disk drive stores data in sectors that held on tracks; all of the tracks at the same distance from the spindle are called a cylinder.
It uses a read/write head attached to a slider, mounted on an actuator arm, to read and write the data as it spins past.