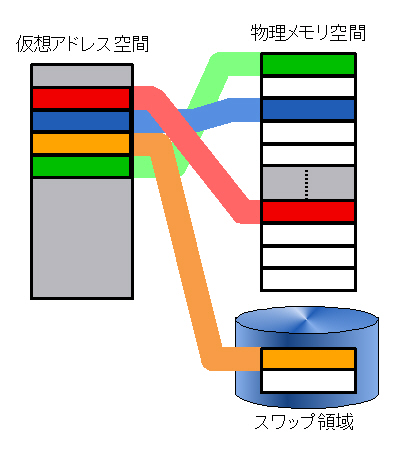
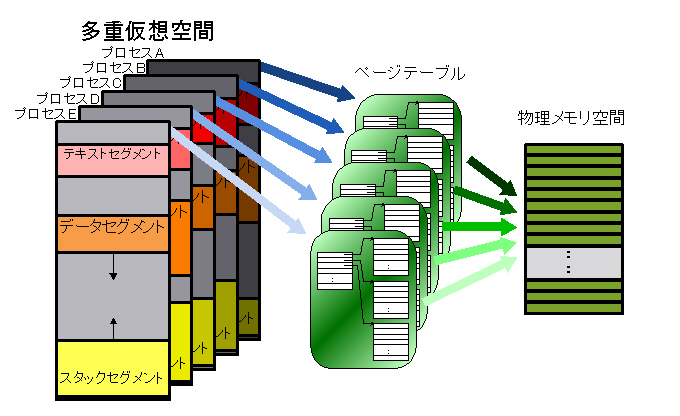
(thanks to Chishiro for spotting those excellent diagrams on Wikipedia.)
The simplest approach would be a large, flat page table with one entry per page. The entries are known as page table entries, or PTEs. However, this approach results in a page table that is too large to fit inside the MMU itself, meaning that it has to be in memory. In fact, for a 4GB address space, with 32-bit PTEs and 4KB pages, the page table alone is 4MB! That's big when you consider that there might be a hundred processes running on your system.
The solution is multi-level page tables. As the size of the process grows, additional pages are allocated, and when they are allocated the matching part of the page table is filled in.
The translation from virtual to physical address must be fast. This fact argues for as much of the translation as possible to be done in hardware, but the tradeoff is more complex hardware, and more expensive process switches. Since it is not practical to put the entire page table in the MMU, the MMU includes what is called the TLB: translation lookaside buffer.
The reference trace is the way we describe what memory has recently been used. It is the total history of the system's accesses to memory. The reference trace is an important theoretical concept, but we can't track it exactly in the real world, so various algorithms for keeping approximate track have been developed.
Paging is the process of moving data into and out of the backing store where the not-in-use data is kept. When the system decides to reduce the amount of physical memory that a process is using, it pages out some of the process's memory. The opposite action, bringing some memory in from the backing store, is calling paging in.
When an application attempts to reference a memory address, and the address is not part of the process's address space, a page fault occurs. The fault traps into the kernel, which must decide what to do about it. If the process is not allowed to access the page, on a Unix machine a segmentation fault is signalled to the application. If the kernel finds the memory that the application was attempting to access elsewhere in memory, it can add that page to the application's address space. We call this a soft fault. If the desired page must be retrieved from disk, it is known as a hard fault.
We can demonstrate OPT pretty easily:
| Time Step | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Reference |  |
 |
 |
|
 |
|
|
|
|
| Page In? | YES | YES | YES | NO | YES | NO | NO | NO | YES |
| Page 0 | |
|
|
|
|
|
|
|
|
| Page 1 | |
|
|
|
|
|
|
|
|
| Page 2 | |
|
|
|
|
|
|
There are many algorithms for doing page replacement algorithms, some of which require extra hardware support. (Most take advantage of the referenced and modified bits in the PTE.) Here are a few:
| Time Step | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Reference | |
|
|
|
|
|
|
|
|
| Page In? | YES | YES | YES | NO | YES | YES | YES | NO | YES |
| Page 0 | |
|
|
|
|
|
|
|
|
| Page 1 | |
|
|
|
|
|
|
|
|
| Page 2 | |
|
|
|
|
|
|
FIFO is pretty obvious: first-in, first-out. If your working set is large enough, it works okay, but if you don't have enough memory, it doesn't work terribly well, but it's easy to implement.
| Time Step | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Reference | |
|
|
|
|
|
|
|
|
| Page In? | YES | YES | YES | NO | YES | NO | YES | NO | YES |
| Page 0 | |
|
|
|
|
|
|
|
|
| Page 1 | |
|
|
|
|
|
|
|
|
| Page 2 | |
|
|
|
|
|
|
According to one source, Linux, FreeBSD and Solaris may all use a very heavily-modified form of LRU. (I suspect this information is out of date, but have not had time to dig through the Linux kernel yet.)
When a clock interrupt is received, all of the R and M bits in all of the page tables of all of the memory-resident processes are cleared. (Obviously, this is expensive, but there are a number of optimizations that can be done.) The R bit is then set whenever a page is accessed, and the M bit is set whenever a page is modified. The MMU may do this automatically in hardware, or it can be emulated by setting the protection bits in the PTE to trap, then letting the trap handler manipulate R and M appropriately and clear the protection bits.
Because NRU does not distinguish among the pages in one of the four classes, it often makes poor decisions about what pages to page out.
I believe early versions of BSD used clock; I'm not sure if they still do.
Early on in the history of virtual memory, researchers recognized that not all pages are accessed uniformly. Every process has some pages that it accesses frequently, and some that are accessed only occasionally. The set of pages that a process is currently accessing is known as its working set. Some VM systems attempt to track this set, and page it in or out as a unit. Wikipedia says that VMS uses a form of FIFO, but my recollection is that it actually uses a form of working set.
In its purest form, working set is an all-or-nothing proposition. If the OS sees that there are enough pages available to hold your working set, you are allowed stay in memory. If there is not enough memory, then the entire process gets swapped out.
Most systems include at least a simple way to set a maximum upper bound on the size of virtual memory and on the size of the resident memory set. On a Unix or Linux system, the shell usually provides a builtin function called ulimit, which will tell you what those limits are. The corresponding system calls are getrlimit and setrlimit. VMS has many parameters that control the behavior of the VM system.
Note that while the other algorithms conceivably work well when treating all processes as a single pool, working set does not.
The Linux kernel goes through many extraordinarily complex operations to find a candidate set of pages that might be discarded. Once it has that list, it applies the following algorithm (Fig. 17.5 from Understanding the Linux Kernel, showing the PFRA):
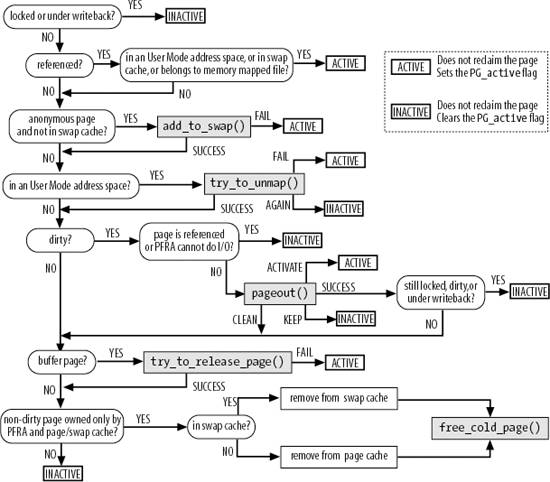
Reviewing:
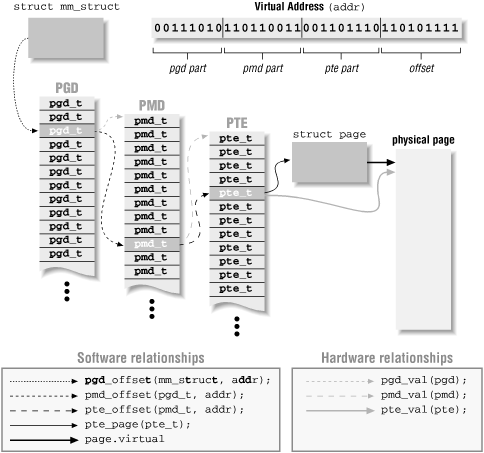
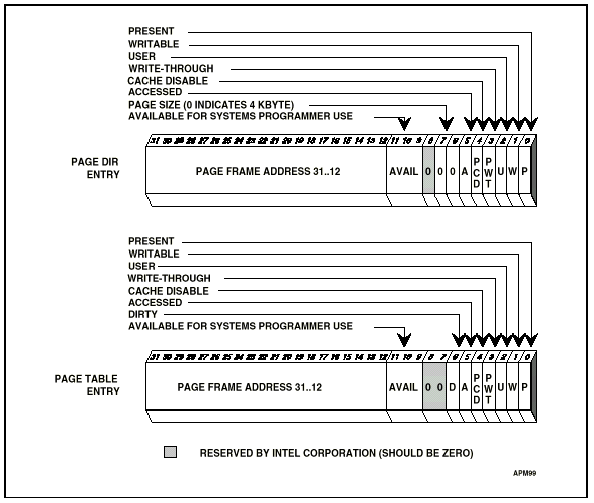
(Images from O'Reilly's book on Linux device drivers, and from lvsp.org.)
We don't have time to go into the details right now, but you should be aware that doing the page tables for a 64-bit processor is a lot more complicated, when performance is taken into consideration.
Linux uses a three-level page table system. Each level supports 512 entries: "With Andi's patch, the x86-64 architecture implements a 512-entry PML4 directory, 512-entry PGD, 512-entry PMD, and 512-entry PTE. After various deductions, that is sufficient to implement a 128TB address space, which should last for a little while," says Linux Weekly News.
#define IA64_MAX_PHYS_BITS 50 /* max. number of physical address bits (architected) */ ... /* * Definitions for fourth level: */ #define PTRS_PER_PTE (__IA64_UL(1) << (PTRS_PER_PTD_SHIFT))
In modern systems, multiple page files are usually supported, and can often be added dynamically. See the system call swapon() on Unix/Linux systems.