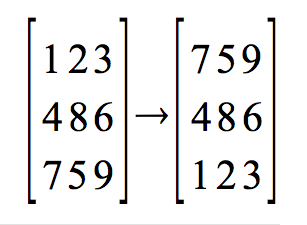
Home >> Advanced Usages on Java Arrays
▼配列そのものを参照する書式たとえば、2つの配列originalとaliasがあり、aliasにoriginalの配列の内容を代入するのには、次のように記述します。
配列名
int original [ ] = { 10, 20, 30, 40, 50 };
int alias [ ] ;
alias = original ; // aliasにoriginalの内容を代入しました
このように、配列同志の代入を行ないますと、結果として両方の配列は、同じ配列の実体を共有することになります。例えば、以下の式では配列変数aと配列変数bは同じ配列の実体を指しています。
int a [ ] = { 10, 20, 30, 40, 50 };
int b [ ] = a;
このような場合、プログラマが把握している分には、大丈夫かも知れませんが、次のように別々に代入をし始めると、一体どこで配列の要素が変更されたのかわかりにくくなります。
public class ArrayTest {
public static void main( String [] arg ) {
int a [] = { 10, 20, 30 ,40, 50 };
int b [] = a;
a[ 4 ] = 60; // 別々に要素に値を代入するが結果的には
b[ 2 ] = 20; // 同じ配列に変更を掛けている
for ( int i=0; iint( "a[ " + i + " ] = " + a[ i ] + " " );
}
System.out.println( "" );
}
}
この例の場合、結果としては、次のような表示がなされます。
a[ 0 ] = 10 a[ 1 ] = 20 a[ 2 ] = 20 a[ 3 ] = 40 a[ 4 ] = 60同じ内容を重複して持っておきたいときは、別々に配列の実体を用意して、次のように繰返しを使って各要素毎に代入をしておく必要があります(注1)。
int a [ ] = { 10, 20, 30 ,40, 50 };
int b [ ] = new int[ a.length ]; // 同じ個数分だけデータ領域を確保しておく
for ( i=0; i < a.length; i++ ) { b[ i ] = a[ i ]; } // 要素を1つずつコピー
図9-7 共有とコピーの図
コピーした場合は、別々に値を重複して持っていますので、一方の配列の要素の値を変更しても、それが他方に影響することはありません。
※注1 配列にはcloneという名前のメソッドが用意されています。これは、コピーを自動的に行なってくれるメソッドですので、繰返しを用いなくても、次のようにしてコピーをつくることができます。
int b [] = ( int [ ] ) a.clone( );
public class DisplayArrayOnConsole {
public static void main( String [ ] args ) {
int a [ ] = new int[ 20 ];
for ( int i =0; i < a.length; i++ ) {
a[ i ] = (int)(Math.random( ) *200 );
}
for ( int i =0; i < a.length; i++ ) {
System.out.print( " " + a[ i ] );
if ( i % 8 == 7 ) { System.out.println( ); }
}
}
}
要素を8個表示するたびに、System.out.printlnメソッドを使って改行するようにしています。前に説明しましたように、繰返しの中で周期的に何かの操作を行ないたいときは、このような剰余演算と条件分岐を用います。
import java.awt.*;
import java.applet.*;
public class DisplayArray extends Applet {
public void paint( Graphics g ) {
int a [ ] = { 10, 34, 82, 95, 3, 4 ,5 ,1,32, -32, 1, 3, 12, 45, 11, 32, 19, -6, 23, 21, 33 };
int width = 30, height = 15;
for ( int i =0; i < a.length; i++ ) {
g.drawString( " " + a[ i ], i % 8 * width , i / 8 * height + 20 );
}
}
}
要素の値を表示するx座標とy座標を技巧的に計算しています。剰余演算はこのように周期的にサイクルさせたいときに使います。また整数除算は、周期毎に1つ値を増やすような場合に使います。次の周期のときには、割り算の結果が1つ大きな値になりますから、表示されるy座標は次の段になります。
import java.awt.*;
import java.applet.*;
public class DisplayGraph extends Applet {
public void paint( Graphics g ) {
int a [ ] = { 10, 34, 42, 55, 3, 4 ,5 ,1,32, 5, 1, 3, 12, 45, 11 };
for ( int i =0; i < a.length; i++ ) {
g.fillRect( 10, i*10 + 10, a[ i ] * 2, 5 );
}
}
}
※横のグラフとして表示しましたが、縦方向にするにはどうしたら良いか考えてください。
図9-8 表示結果
public class Summetion {
public static void main( String [ ] arg ) {
int sum, a [ ] = { 5, 2, 565, 222, 111, 344, 22, 99, 348, 222 };
sum = 0;
for ( int i= 0; i < a.length; i++ ) {
sum = sum + a[ i ];
}
System.out.println( "要素の値の総和は" + sum + "平均は" +
((double) sum / a.length) + "です。" );
}
}
public class SeekMaximum {
public static void main( String [ ] args ) {
int max;
int a [ ] = { 5, 2, 565, 222, 111, 344, 22, 99, 348, 222 };
max = 0;
for ( int i= 1; i < a.length ; i++ ) {
if ( a[ max ] < a[ i ] ) { max = i; }
}
System.out.println( "最大の要素は" + max + "番目で、その値は"
+ a [ max ] + "です。" );
}
}
この方法は、「さらに良い条件の人が現れたら、そちらの人に乗り換える」という打算的な恋愛者のポリシーと同じです。そのような恋愛者は、各時点で、今まで現れた一番良い条件の人とつきあっている筈でしょう(理論的には)。
※最小値を求めるためにはどうしたらよいか考えてみてください。
public class SeekTarget {
public static void main( String [ ] args ) {
int target = 22;
int a [ ] = { 5, 2, 565, 222, 111, 344, 22, 99, 348, 222 };
int index = 0;
for ( ; index < a.length; index++ ) {
if ( a[ index ] == target ) { break; }
}
if ( index < a.length ) {
System.out.println( target + "は" + index + "番目にありました" );
} else {
System.out.println( target + "はありません!" );
}
}
}
public class ValueCounter {
public static void main( String [ ] args ) {
int target = 33;
int a [ ] = { 5, 33, 565, 33, 111, 344, 22, 99, 348, 33 };
int count = 0;
for ( int index = 0; index < a.length; index++ ) {
if ( a[ index ] == target ) { count++; }
}
System.out.println( target + "は" + count + "個ありました" );
}
}
※上記プログラムをある値よりも大きい(小さい)要素が何個あるか数えるように、変えてみなさい。
public class ElementShifter {
public static void main( String [ ] args ) {
int a [ ] = new int[ 100 ];
for ( int index = 0; index < a.length; index++ ) { a[ index ] = index + 1; }
for ( int i = 0; i < a.length * 2; i++ ) {
int index1 = (int)( Math.random( ) * a.length );
int index2 = (int)( Math.random( ) * a.length );
int temp = a[ index1 ];
a[ index1 ] = a[ index2 ];
a[ index2 ] = temp;
}
}
}
public class FrequencyCounter {
public static void main( String [ ] args ) {
int birth [ ] = { 1, 3, 5, 2, 8, 11, 4, 6, 7, 9, 8, 10, 12, 1, 4, 5, 3, 2, 1, 8, 9, 5, 6, 7, 12, 4, 2};
int month [ ] = new int [ 13 ];
for ( int i = 1; i < month.length; i++ ) { month[ i ] = 0; }
for ( int index = 0; index < birth.length; index++ ) {
month[ birth[ index ] ]++;
}
for ( int i = 1; i < month.length; i++ ) {
System.out.println( i + "月の誕生日の人は" + month[ i ] + "人いました" );
}
}
}
import java.awt.*;
import java.applet.*;
public class FrequencyGraph extends Applet {
public void paint( Graphics g ) {
int data [ ] = { 10, 34, 42, 55, 33, 0, 64 ,57 ,1, 32, 59, 100, 61, 3, 12, 45, 11, 97 };
int partition =10, minimum = 0, maximum = 100;
int frequent [ ] = new int [ (maximum + partition - minimum)/ partition ];
for ( int i = 0; i < frequent.length; i++ ) { frequent[ i ] = 0; }
for ( int index = 0; index < data.length; index++ ) {
for ( int i = 0; i < frequent.length ; i++ ) {
if ( data[ index ] < minimum + partition * (i+1) ) {
frequent[ i ]++; break;
}
}
}
for ( int i =0; i < frequent.length; i++ ) {
g.drawString( "< " + (minimum + partition * (i+1)) , 10, i*20 + 15 );
g.fillRect( 50, i*20 + 10, frequent[ i ] * 2, 5 );
g.drawString( ""+ frequent[ i ] , 50 + frequent[ i ] * 2 + 5, i*20 + 15 );
}
}
}
※partitionや、minimumあるいはmaximumの初期値をいろいろ変えてみて、どのような場合でも動くことを確認しなさい。定められた値の範囲で、配列dataのデータの個数を増やしてみなさい。
例:
void scanArray( int a [ ] ) { ..... } // 整数の配列を引数として貰う
int [ ] getArray( ) { ....... } // 整数の配列を戻り値として返す
メソッドを呼び出す方では、実パラメータの中に配列名を記述します。
int a [ ] = { 10, 20, 22, 5, 6 }; // ローカルな配列の定義
scanArray( a ); // 配列aを引数として渡している
int b [ ] = getArray( ); // 戻り値から、配列bを設定している
▼オブジェクト配列の宣言の書式たとえば、次の2つの配列は、それぞれカラーとボタン用の配列となります。
Color colors [ ] = new Color[ 20 ]; // 20個のカラーオブジェクト用の配列 Button buttons [ ] = new Button[ 10 ]; // 10個のボタンオブジェクト用の配列後は、通常の配列のように用いることができます。配列の要素を指定する場合は、通常のオブジェクトを参照している変数のように用いることができます。
class="program">
colors[ 3 ] = new Color( 10, 30, 40 ); // 3番目の要素にカラーオブジェクトを生成
g.setColor( colors[ 3 ] );
for ( int i = 0; i < buttons.length; i++ ) { // 配列のすべてのボタンに対して
buttons[ i ] = new Button( "Proceed "+ i ); // 個々の要素にボタンオブジェクトを生成
buttons[ i ].addActionListener( this ); // アクションリスナーを設定
add( buttons[ i ] ); // アプレットの画面上に配置
}
上の例をみてもわかるように、オブジェクトの配列は、オブジェクトそのものを生成したのではありません。new文では配列を1つ生成にしただけに過ぎません。ですから、配列の要素となる個々のオブジェクトは、その都度繰返しなどを使ってnew文を使ってそれぞれを生成していく必要があります。これが、通常の整数などの配列と異なる点です。
▼配列の要素のオブジェクトのメソッドを呼び出す書式
配列名[ インデックスの式 ].メソッド名( 実引数 )
GraphicsEnvironment env = GraphicsEnvironment.getLocalGraphicsEnvironment( ); Font allfonts [ ] = env.getAllFonts( );このようにすれば、後はオブジェクトの配列に対して処理するだけです。たとえば、端末画面にそれらのフォントの名前を全部表示するのには、getNameメソッドを利用します。
for ( int i=0; i < allfonts.length ; i++ ) {
System.out.println( allfonts[ i ].getName( ) );
}
▼配列の要素のオブジェクトのインスタンス変数を参照する書式たとえば、次のような10個の要素を持つPointクラスのオブジェクトが次のようなプログラムの断片によって、用意されているとしましょう。
配列名[ インデックスの式 ].インスタンス変数名
Point points [ ]= new Point[ 10 ];
for ( int i=0; i< points.length ; i++ ) {
points[ i ] = new Point( (int)(Math.random( )*200) , (int)(Math.random( )*100) );
}
この配列の要素であるオブジェクトのインスタンス変数を参照してみましょう。
points[ 0 ].x = 45; points[ 6 ].x = points[ 3 ].x + 12; System.out.println( "Fifth point x-axis: " + points[ 5 ].x + "y-axis:" + points[ 5 ].y );さらに繰返しを使って、各点を線で結んでみましょう(アプレットのpaintメソッドの中で実行されていて、描画領域を仮パラメータ変数gで受け取っているとします)。
for ( int i=0; i< points.length - 1 ; i++ ) {
g.drawLine( points[ i ].x , points[ i ].y, points[ i + 1].x, points[ i + 1 ].y );
}
上の繰返しですと、最初(0番目)の点と最後(9番目)の点を結んでくれません。この2つの点を結んで閉じた形にするには、余りの演算を使って次のようにします。どうしてうまくいくかは、考えてみてください。
for ( int i=0; i< points.length; i++ ) {
g.drawLine( points[ i ].x , points[ i ].y,
points[ (i + 1) % points.length ].x, points[( i + 1) % points.length ].y );
}
図9-1 閉包になるように点を結んだ例
Point myPoints [ ] = { new Point( 33, 22 ), new Point( 22 , 11 ), new Point( 55, 19 ) };
これは、以下の記述と等価です。注意しなければならないのは、配列をnew演算子で作成した後、更に個々の要素をnew演算子で作成しなければならないことです。配列の生成と個々のオブジェクトの生成は別であるということを再認識しましょう。
Point myPoints [ ] = new Point [ 3 ]; myPoints[ 0 ] = new Point( 33, 22 ); myPoints[ 1 ] = new Point( 22 , 11 ); myPoints[ 2 ] = new Point( 55, 19 );また、Java 2以降は、配列の宣言と初期値の代入を別々に行なうことができます。これは、配列の章で説明しました。初期値代入をしたい場合は、new演算子を利用することになります。
Point myPoints;
myPoints = new Point [ ] { new Point( 33, 22 ), new Point( 22 , 11 ), new Point( 55, 19 ) };
▼配列を受け取るメソッド定義の書式配列を利用した例を考えてみましょう。例えば、次のメソッドは、論理値を返します。配列と、ある値が引数として与えられ、配列の要素がすべて、引数として与えられた値よりも大きかったら、trueを返します。そうでなければ、falseを返します。要素を調べていって1つでも小さい要素が見つかったらfalseを返して終了するようにしています。繰返しが最後まで終わったら、見つからなかったということでtrueを返しています。
voidあるいは型名あるいはクラス名 メソッド名( 配列の仮引数の宣言, … ){
}
boolean isAllGreater( int a [ ], int value ) {
for ( int i=0; i< a.length; i++ ) {
if ( a[ i ] < value ) { return false; }
}
return true;
}
これを利用してみましょう。
int array [ ] = { 18, 20, 40, 50, 30, 40 };
if ( isAllGreater( array, 15 ) ) { ........ } // すべての値が15よりも大きかったら
次の例は、整数を返すメソッドですが、さきほどと同じように、配列と、ある値が引数として与えられ、もし配列の中にその値が存在したら、最初に見つかった要素のインデックスの値を返します。もしなければ、-1を返します。中身も、先程のメソッドと似ています。
int scanValue( int a [ ], int value ) {
for ( int i=0; i< a.length; i++ ) {
if ( a[ i ] == value ) { return i ; }
}
return -1;
}
これを利用してみましょう。
int array [ ] = { 18, 20, 40, 50, 30, 40 };
int target = scanValue( array, 40 );
System.out.println( "Target Index:" + target );
▼オブジェクトを返すメソッド定義の書式例えば、前出のPointクラスのオブジェクトを返すようなメソッドは次のように定義します。
クラス名 メソッド名( 仮引数の宣言, … ){
return オブジェクト;
}
Point sample( ) { ...... } // メソッドの定義
このようなメソッドを利用する呼出し側では、結果のオブジェクトを保持するための変数を用意して、代入します。下の例では変数の宣言も同じに行なっています。
Point result = sample( ); // メソッドを呼び出して利用するメソッドが、配列あるいはオブジェクトの配列を、呼出し側に返すときは次のように指定します。
▼基本型あるいはオブジェクトの配列を返すメソッド定義の書式またもや前出のPointクラスのオブジェクトを返すようなメソッドを定義してみます。
型名あるいはクラス名 [ ] メソッド名( 仮引数の宣言, … ){
return 配列名;
}
Point [ ] sampleList( ) { ...... } // メソッドの定義
このメソッドを呼び出す方では、オブジェクトの配列を保持するような変数を用意して、戻り値を代入するようにします。下の例では変数の宣言も同じに行なっています。
Point resultlist [ ] = sampleList( ); // メソッドを呼び出して利用する
ここでは、正方行列(列数と行数がおなじ)ものを中心に、行列の足し算、引き算、行列の掛け算、行列式を求める計算方法を紹介します。 行列式を求める方法は、ガウスの前進消去と似ていますが、LU分解の方法で求めています。 また、すべて2次元配列を受け取るメソッドの形で記述しています。 まず、呼び出す側では、次のような設定で、乱数で2次元配列が初期化されていると仮定します。 行列計算ですので、当然のことながら、配列の要素は実数型になっています。 以下の記述では、5次の正方行列になっています。 タートル・グラフィックスのライブラリを使うのであれば、以下の記述はstartメソッドの中に記述してください。
int size = 5;
double n[ ][ ] = new double[ size ][ size ];
double m[ ][ ] = new double[ size ][ size ];
double r[ ][ ] = new double[ size ][ size ]; // 結果用の2次元配列
double magnitude = 10; // 配列の各要素が最大どれくらいの大きさか
// 2つの行列の乱数値による初期化
for ( int i=0; i < n.length ; i++ ) {
for ( int j=0; j < n[ i ].length; j++ ) {
n[ i ][ j ] = Math.random( ) * magnitude;
m[ i ][ j ] = Math.random( ) * magnitude;
}
}
もし、行列の値を表示したければ、次のようなメソッドを定義して呼び出してください。 次のメソッドは、1つの2次元配列と次数(正方行列の大きさ、この場合は5です)を引数として受け取ります。 このメソッドは、Java 5から定義された、System.out.printfを使っています。printfは、C/C++言語と似ていますので、 それらの言語を学んだときに思い起こせるのではないでしょうか。この記述は、引数を実数(f)として受け取り、 整数部最大3桁、小数部最大5桁という形で実数をターミナル(文字端末)に表示するように指定しています。 次の行列を表示するときのことを考慮して、最後に再度改行して、空行を1つ用意しています。
void printSquareMatrix( double mat[ ][ ], int size ) {
for ( int i=0; i < size ; i++ ) {
for ( int j=0; j < size ; j++ ) {
System.out.printf( "%3.5f ", mat[ i ][ j ] );
}
System.out.println( );
}
System.out.println( );
}
使い方は、至って単純で、上記の乱数で設定された2つの2次元配列を表示する場合は、次のように呼び出します。 タートル・グラフィックスのライブラリを使うのであれば、以下の記述はstartメソッドの中に記述してください。
printSquareMatrix( n, size ); printSquareMatrix( m, size );
加減算は、簡単なメソッドとして記述できます。正方行列として表現された2次元配列のそれぞれの要素を足したり、 引いたりするだけです。以下は、2つの2次元配列と結果をいれる2次元配列、および次数を受け取り、加減算を行なう メソッドです。2つのメソッドを定義していますが、両者の違いは、ネストされたfor文の中で要素を足しているのか、引いているのかの 違いだけです。
void addSquareMatrix( double n[ ][ ], double m[ ][ ], double r[ ][ ], int size ) {
for ( int i=0; i < size ; i++ ) {
for ( int j=0; j < size; j++ ) {
r[ i ][ j ] = n[ i ][ j ] + m[ i ][ j ];
}
}
}
void subSquareMatrix( double n[ ][ ], double m[ ][ ], double r[ ][ ], int size ) {
for ( int i=0; i < size ; i++ ) {
for ( int j=0; j < size; j++ ) {
r[ i ][ j ] = n[ i ][ j ] - m[ i ][ j ];
}
}
}
それでは、先ほどのnとmとrを使って、呼び出してみましょう。 タートル・グラフィックスのライブラリを使うのであれば、以下の記述はstartメソッドの中に記述してください。
addSquareMatrix( n, m, r, size ); printSquareMatrix( r, size ); subSquareMatrix( n, m, r, size ); printSquareMatrix( r, size );
行列の積は、ちょっと面倒でした。最初の行列は横方向に、掛け算を行なう次の行列は縦方向に、 各要素を掛け算して、その総和を、結果の行列の対応する要素に入れるものでした。 通常の掛け算と違って、交換則(AB=BA)が成り立たないのも特徴ですし、行列の構造によっては、 乗算が成立しない可能性もありました(最初の行列の列数と、次の行列の行数が等しくなければならない)。 この場合は、正方行列ですから、乗算は成立しますが、いかんせん、積を求めるのは面倒ですね。 以下は、2つの正方行列を2次元配列として受け取り、3つ目の2次元配列に積を求めるものです。 次数も引数として指定しています。
void multiplySquareMatrix( double n[ ][ ], double m[ ][ ], double r[ ][ ], int size ) {
for ( int i=0; i < size ; i++ ) {
for ( int j=0; j < size; j++ ) {
r[ i ][ j ] = 0;
for ( int k=0; k < size; k++ ) {
r[ i ][ j ] = r[ i ][ j ] + n[ i ][ k ] * m[ k ][ j ];
}
}
}
}
上記のように、ネストが1つ深くなっています。5次だと検算するのも嫌ですね。以下は呼び出して、その結果を表示させています。 ここで、合っているかどうか、疑り深い人は、sizeの部分を1とか、2などを記述して、部分的に検算してみては いかがと思います。テストするときも、そのようにして検算しました。
multiplySquareMatrix( n, m, r, size ); printSquareMatrix( r, size );
さあ、ここからが本番で面倒です。受け取った正方行列をLU分解 しています。LU分解って何?っていう人は、取り合えず、正方行列をLという行列とUという行列に分解すると、計算が楽になると思って下さい。 ちなみに、LとUの積を取りますと、元の正方行列に戻ります。さらに、行列Lは対角成分がすべて1の下三角行列、 行列Uは、上三角行列になっていますので、行列Uの対角成分の要素の積を計算すれば、それが行列式の答えになります。 まずは、LUに分解するメソッドを定義します。 実は、LU分解するときには、0で割って発散しないように、注意深く要素を選ばなければなりません。 対角成分の要素をPivot(ピボット)と呼びます。 0や絶対値が0に近い値を持つピボットで割ってはいけないので、行列の行の入れ替えをして、ピボットを一番大きい絶対値を持つ 行の値を使うようにします。
int swapcount=0; // 入れ替えをしたカウント(行列式の計算のために)
boolean decomposeLU( double n[ ][ ], double L[ ][ ], double U[ ][ ], int size ) {
// 単位行列IをLに設定し、Uにnのコピーを作ります
for ( int i=0; i < size; i++ ) {
for ( int j=0; j < size; j++ ) {
L[ i ][ j ] = ( i==j ) ? 1.0 : 0.0;
U[ i ][ j ] = n[ i ][ j ];
}
}
swapcount = 0;
// ピボットで絶対値が一番大きいものを探しだし、行を入れ替えます
double epsilon = 1.0e-10;
for ( int i=0; i < size; i++ ) {
// 絶対値が一番大きいピボットを求めます
int max = i;
for ( int j=i+1; j < size; j++ ) {
if ( Math.abs( U[ max ][ i ] ) < Math.abs( U[ j ][ i ] ) ) {
max = j;
}
}
/ / もし最大絶対値を持つピボットが0に近ければ、LU分解できないことを告げます
if ( U[ max ][ i ] >= -epsilon && U[ max ][ i ] <= epsilon ) { return false; }
// 最大絶対値のピボットを持つ行と、i番目の行を入れ替えます
for ( int j=0; j < size; j++ ) {
double temp = U[ i ][ j ];
U[ i ][ j ] = U[ max ][ j ];
U[ max ][ j ] = temp;
}
if ( max != i ) { swapcount++; }
}
// ガウスの消去法(掃き出し法)を使って、LとUに分解します
for ( int k=0; k < size-1; k++ ) {
for ( int i=k+1; i < size; i++ ) {
L[ i ][ k ] = U[ i ][ k ]/U[ k ][ k ];
U[ i ][ k ] = 0;
for ( int j=k+1; j < size; j++ ) {
U[ i ][ j ] = U[ i ][ j ] - U[ k ][ j ] * L[ i ][ k ];
}
}
}
return true;
}
LU分解の仕方ですが、最初は行列Lは、対角成分が1.0である正方行列(一般にはIで表わされる)から始めます。 行列Uは、分解する行列nのコピーで良いでしょう。次の1から9までの数字で構成される3次正方行列をLU分解してみます。 最大絶対値を持つピボットと置き換えるため、次のように、第1行と第3行が入れ替えされています。
これを、各対角成分の値でガウスの消去法(掃き出し法)を使って、 LとUに分解していきます。まず、第1行のピボットの値7と、 第2行の最初の値4を使って、第2行を計算します。次に、第1行のピボットの値7と、第3行の最初の値を1を使って、 第3行を計算します。最後に第2行のピボットの値8と、第3行の2列目の値2を使って、第3行の3列目の値を求めています。

それでは、上記の3次正方行列を分解するサンプルプログラムを記述してみましょう。 まずは、元の行列(N)を表示して、分解されたLとUの行列を表示し、最後にLとUの積を求めています。 元のNと等しいのがわかると思います。
int degree=3; // 3×3の正方行列を示します
double n[ ][ ] = new double [ ] [ ] { {1, 2, 3}, {4, 8, 6}, {7, 5, 9} };
double L [ ][ ] = new double[ degree ][ degree ];
double U[ ][ ] = new double[ degree ][ degree ];
System.out.println( "N:" );
printSquareMatrix( n, degree );
if ( decomposeLU( n, L, U, degree ) ) {
System.out.println( "L:" );
printSquareMatrix( L, degree );
System.out.println( "U:" );
printSquareMatrix( U, degree );
System.out.println( "L×U:" );
double r[ ][ ] = new double[ degree ][ degree ];
multiplySquareMatrix( L, U, r, degree );
printSquareMatrix( r, degree );
}
行列式を求めるメソッドは、LU分解して、行列Uの対角成分の要素の積を求めているだけです。 ただし、LU分解された際の行の移動の回数が奇数の場合は、マイナスを掛けます。
double determinant( double n[ ][ ], int size ) {
if ( size == 1 ) { return n[ 0 ][ 0 ]; }
double L[ ][ ] = new double[ size ][ size ];
double U[ ][ ] = new double[ size ][ size ];
if ( decomposeLU( n, L, U, size ) ) {
double result = 1.0;
for ( int i=0; i < size; i++ ) {
result *= U[ i ][ i ];
}
if ( swapcount % 2 != 0 ) { result = -result; }
return result;
} else return 0;
}
先ほどの配列について求めるような記述を追加してみてください。値としては、「-54」が求まる筈です。
double det = determinant( n, degree ); System.out.println( det );
LU分解できてしまえば、逆行列は、U-1にL-1を掛けることで求まります。 などと言っても、UやLの逆行列を求めるのも大変です。本当は、LU分解を使って、掃き出し法で求めるのですが、 ここは大学の行列の教科書に従って、行列式と余因子行列の行列式を使って求めてみましょう。 なお、逆行列が存在する必要充分条件は、行列の行列式が0ではないということです。
void inverse( double n[ ][ ], double r[ ][ ], int size ) {
double det = determinant( n, size );
if ( det == 0.0 ) { return; }
for ( int i=0; i < size; i++ ) {
for ( int j=0; j < size; j++ ) {
r[ j ][ i ] = detCofactor( n, i, j, size ) / det;
}
}
}
double detCofactor( double n[ ][ ], int row, int column, int size ) {
if ( size == 1 ) { return n[ row ][ column ]; }
double cofactor [ ][ ] = new double[ size-1 ][ size-1 ];
for ( int i=0, ii=0; i < size; i++, ii++ ) {
if ( i==row ) { i++; }
for ( int j=0, jj=0; j < size; j++, jj++ ) {
if ( j==column ) { j++; }
cofactor[ ii ][ jj ] = n[ i ][ j ];
}
}
return determinant( cofactor, size-1 )* (((row+column)%2==0)? 1 : -1);
}
最後に検証として、逆行列を求めて、元の行列と乗算をして、単位行列(対角成分だけが1で、他はすべて0)が出てくるかどうか 確かめてみましょう。
inverse( n, r, size ); printSquareMatrix( r, size ); double ident[ ][ ] = new double[ size ][ size ]; multiplySquareMatrix( n, r, ident, size ); printSquareMatrix( ident, size );
上記のメソッドの中で、配列の特徴を持つのは、getメソッドとsetメソッドです。配列の要素への参照と代入を示しています。なお、getメソッドで返されたオブジェクトは、Objectクラスのオブジェクトになっていますので、「(目的のクラス名)(オブジェクトを指す変数.get( インデックス ))」という形でクラス変換をする必要があります。addメソッドとremoveメソッドは、リストの特徴を持っています。要素を追加したり、削除したりできます。削除された要素の後に続くすべての要素のインデックスは、1つ前にずれてくれます。
int size( ) 集合の中のオブジェクトの個数を返します boolean contains( Object element ) 集合の中に、そのオブジェクトがあるかどうか Object [ ] toArray( ) 集合をオブジェクトの配列に変換します boolean isEmpty( ) 集合が空かどうか返します boolean add( Object element ) リストの最後に要素を追加する void add( int index, Object element ) 指定されたインデックスの後に要素を追加する Object remove( int index ) 指定されたインデックスの要素を削除する Object get( int index ) 指定されたインデックスの要素を取り出す Object set( int index, Object element ) 指定されたインデックスの要素を取り替える List subList( int fromindex, int toindex ) 一部分のリストを取り出す int indexOf( Object target ) 対象の要素が何番目にあるか返す int lastIndexOf( Object target ) 対象の要素で最後に該当するものが何番目か
import java.util.*; // ArrayListはjava.utilパッケージに入っています ArrayList<Integer> valuelist = new ArrayList<Integer>( ); // Integerクラスの要素を持つArrayListを作る valuelist.add( new Integer( 123 ) ); // 要素を1つ追加する int value = linelist.get( 0 ).intValue( ); // 0番目の要素を獲得し、その整数値を変数に代入する
import java.awt.*;
import java.applet.*;
import java.awt.event.*;
import java.net.*;
import java.io.*;
import java.util.*;
public class ListReader extends Applet implements ActionListener {
ArrayList<String> linelist; // Java 6.0からは要素のクラス<String>を付ける必要があります
TextField result;
int current = 0;
public void init() {
linelist = new ArrayList<String>();
try {
URL address = new URL( getCodeBase( ), "info" );
BufferedReader br = new BufferedReader(
new InputStreamReader( address.openStream( ) ) );
while ( br.ready( ) ) {
String line = br.readLine( );
linelist.add( line );
}
br.close( );
} catch( Exception exc ) {
exc.printStackTrace( );
}
Button proceed = new Button( "Go Next" );
proceed.addActionListener( this );
add( proceed );
result = new TextField( 60 );
result.setText( (current+1) + ": " +(String) (linelist.get( current ) ) );
add( result );
}
public void actionPerformed( ActionEvent ae ) {
current = (current + 1) % linelist.size( );
result.setText( (current+1)+ ": " + (String) (linelist.get( current ) ) );
repaint( );
}
}
String fickle = "最初の人" ; fickle = "次の人" ; fickle = "更に次の人" ;参照されなくなった文字列定数は、参照されなくなったオブジェクトと同様にいずれガベージコレクションの機構によって、メモリ上から廃棄されることになります。
String combined = "おせちもいいけど" + "カレーもね" ; String complicated = "文字と”+ '数' + 30 + "や実数" + 4.5e3 + "を結合" ; System.out.println( combined + complicated );文字列変数に対して自己再帰的なの加算演算もできます。以下の例では、変数extendedは毎行異なる文字列を指していくことを注意してください。この例では、結合の計算結果として発生する新しい文字列を参照していくことために、前に代入された文字列は参照されなくなります。
String extended = "うらら"; extended = extended + "うらら"; // "うららうらら" を新しく参照する extended += "うらうらら"; // "うららうららうらうらら" を新しく参照する文字列の演算で有効なものは、この加算演算しかありません。減算や乗算などの演算子はありませんし、==や>などの比較演算も、オブジェクトの識別子の比較になってしまうので、文字列の比較にならず、意味を持ちません。文字列の一部を取り出したり、文字列どうしを比較するためには、Stringクラスに用意されているいくつかのメソッドを利用します。
▼サイズを知るための式たとえば、次のように文字列変数に定数を代入して、文字数を得ることができます。最初の方のlengthメソッドの呼出しでは、文字列が17文字から構成されていますので、変数lengthofmakiには17が代入されます。この例では、わかりやすくするために、一旦整数の変数にサイズを代入していますが、直接maki.length( )をその下の行のSystem.out.printlnの引数の中に入れても構いません。また、その下の例のように、文字列定数に対して直接lengthメソッドを呼び出すことができます。この場合は、6という結果が返ってきます。
文字列.length( )
String maki= "ああ、やんなっちゃう、ああ、驚いた"; int lengthofmaki = maki.length( ); System.out.println( "文字変数makiの中の文字数は" + lengthofmaki ); System.out.println( "この文字数は" + "この文字数は".length( ) );
equals( 文字列 ) 等しいかどうかこれらのメソッドは、満足する場合は、trueを返してきます。満足しない場合は、falseを返してきます。各メソッドを用いてみましょう。
equalsIgnoreCase( 文字列 ) 等しいかどうか(大文字小文字の別は無視する)
endsWith( 文字列 ) その文字列で終了するかどうか
startsWith( 文字列 ) その文字列で開始するかどうか
String plane = "F16 Falcon";
if ( plane.equals( "F16 Falcon" ) ) { System.out.println( "Air Force Fighter" ); }
else if ( plane.equals( "F18 Hornet" ) ) { System.out.println( "Navy Fighter" ); }
else { System.out.println( "Is this a current airplane of US ?" ); }
このequalsメソッドは、前の章の音声ファイルの例題のボタンのラベルを変更するアプレットや時間計測のアプレットで、ボタンに設定されたラベルの文字列を比較するために用いられています。
String mytext = "Igor Stranvinsky";
if ( mytext.equalsIgnoreCase( "IGOR STRAVINSKY" ) ) {
System.out.println( mytext + " composed the Fire Bird." );
}
String message = "When did you stop eating?";
if ( message.endsWith( "playing?" ) ) // false
{ System.out.println( "Oh, I am just thinking that I have to study." ); }
if ( message.startsWith( "When" ) ) // true
{ System .out.println( "I will stop everything before noon" ); }
compareTo( 文字列 ) 文字列の辞書順を指定した文字列と比べるこのメソッドは、整数を返してきます。指定した文字列よりも辞書順で先であれば負の数を返してきます。また、等しい文字列なら0を返してきます。辞書順で後になるならば、正の数を返してきます。
String source = "This is a small message."; int result1 = source.compareTo( "This" ); // 結果は正の数 int result2 = source.compareTo( "No, it's long." ); // 結果は正の数 int result3 = source.compareTo( "This is a small message." ); // 結果は0 int result4 = source.compareTo( "This is not a small message." ); // 結果は負の数 int result5 = source.compareTo( "What is the message?" ); // 結果は負の数負の数、正の数が一体どの数になるかは決まっていません。ですから、if文などで用いるときは、次のように0との不等号で判別する必要があります。
String target = "Rabbit" ;
if ( target.compareTo( "Lion" ) > 0 ) { System.out.println( "Lion proceeds the target" ); }
if ( target.compareTo( "Turtle" ) < 0 ) { System.out.println( "Turtle follows the target" ); }
文字列.substring( 開始位置, 終了直後の位置 ) あるいは開始位置(0〜length( ) -1の範囲)から、終了位置(0〜length( )の範囲)の手前までの文字列を取り出してくれます。取り出すのが終了直後の位置の「1文字分手前」であるということに注意してください。終了直後の位置を省略すると、開始位置から文字列の最後までを取り出してくれます。もちろん、取り出した後の文字列は別の文字列として生成されますので、元の文字列は変わらないで残されます。 次の例は、3文字目から9文字目を取り出したものと、7文字目以降最後までを取り出したものです。
文字列.substring( 開始位置 )
String message = "Sample Message"; System.out.println( message.substring( 3, 10 ) ); // "ple Mes" System.out.println( message.substring( 7 ) ); // "Message"先頭の5文字分だけ取り出したいとき、あるいは最後の5文字分だけ取り出したいときは、それぞれ次のように指定します。最後の何文字かだけ取り出したいときは、パラメータが1つだけの方のsubstringを使い、lengthメソッドと用いてサイズを求め、そこから文字数分を引くようにして、開始位置を計算しています。
String firstFive = message.substring( 0, 5 ); // "Sampl" 最初の5文字 String lastFive = message.substring( message.length( ) - 5 ); // "ssage" 最後の5文字
位置を指定して文字を参照するための式たとえば、次のようにすれば、それぞれ、先頭の文字、最後の文字を求めることができます。配列のインデックスと同じで、位置は0から始まることに注意してください。
文字列.charAt( 位置の式 )
String crazyCats = "わかっちゃいるけど、やめられない"; char firstchar = crazyCats.charAt( 0 ); // 'わ' char lastchar = crazyCats.charAt( crazyCats.length( ) - 1 ); // 'い'charAtメソッドとsubstringメソッドとの違いに注意してください。substringメソッドでも1文字を取り出すことができますが、取り出した結果は、文字列です。charAtメソッドの場合は、取り出した結果は文字になっています。
String katochan = "ちょっとだけよ" ; String fourth = katochan.substring( 3, 4 ); // "と" ←文字列 char fourthchar = katochan.charAt( 3 ); // 'と' ←文字
String takostr = " 蛸はどうした?";
for ( int i =0; i < takostr.length( ); i++ ) {
System.out.println( i + "番目の文字は" + takostr.charAt( i ) + "です。" );
}
String message = "This is a sample message";
int wordcount = 1;
for ( int i=0; i < message.length( ); i++ ) {
if ( message.charAt( i ) == 32 ) { wordcount++; } //空白が現れたら単語数を増やす
}
System.out.println( message + "の単語の数は" + wordcount );
上の例で、if文の中で32と比較しているのは、空白のUnicodeでの文字コードは32だからです。この部分を、次のように空白一個分を開けた文字定数を用いて記述しても構いません。
if ( message.charAt( i ) == ' ' ) { wordcount++; }
indexOf( 探したい文字または文字列 ) あるいは実際の例を見てみましょう。次のプログラムの断片は、「桃」という字を2回探しています。
indexOf( 探したい文字または文字列, 探し始める位置 )
String message = "桃も李も桃のうち"; int search = message.indexOf( '桃' ); // 結果は0 int search2 = message.indexOf( '桃', search+1 ); // 結果は4 int search3 = message.indexOf( "桃の" ); // 文字列の場合、結果は4
String original = "私は鮪を食べたいのです。" ; String modified = original.substring( 0, 2 ) + '鰹' + original.substring( 3 ); // →"私は鰹を食べたいのです。"という文字列が新しく生成されるこのように、Stringクラスは、一定の文字列を効率的に処理をするために設計されており、既存の文字列を書き換えることを想定していません。そのため、文字列の個々の文字を頻繁に変更するような場合は、非効率的になります。そのような用途には、StringクラスのサブクラスであるStringBufferクラスを用います。
String message= "This is a simple message"; System.out.println( message.toLowerCase( ) ); // "this is a simple message" System.out.println( message.toUpperCase( ) ); // "THIS IS A SIMPLE MESSAGE"
String whiteSpace = " Snow in the north field. "; System.out.println( whiteSpace.trim( ) ); // "Snow in the north field"
String 受け取る変数 = replace( 古い文字, 新しい文字 )指定した文字をすべて取り替えてくれます。実際の例を見てみましょう。次のプログラムの断片は、「桃」を「蛸」に置き換えた新しい文字列を生成してくれます。
String message = "桃も李も桃のうち"; String mymessage = message.replace( '桃', '蛸' ); // "蛸も李も蛸のうち"
StringBuffer buffer = new StringBuffer( "A sample message" );あとは通常のStringクラスの変数のように用いることができます。ただし、printLineなどにするときは、文字列と足し算するか、キャストを使って(String)に変換しないと使えません。通常は、Stringクラスの文字列が求められているからです。しかし、その不便さを補うかのように、StringBufferクラスのオブジェクトには、文字単位で文字列を変更するためのsetCharAtメソッドやreplaceメソッドが用意されています。以下のように使います。
文字単位で変更する書式文字の位置は、配列と同様に0〜文字列のサイズ-1の間で指定することができます。このメソッドを用いて変数に代入されている文字列を1文字単位で変更させることができます。文字単位で頻繁に文字の変更がある場合は、StringBufferクラスを用いた方がよいでしょう。StringBufferクラスはStringクラスのサブクラスですので、Stringクラスのオブジェクトで利用できるすべてのメソッドが利用可能になっています。
StringBufferクラスの変数.setCharAt( 文字 )
StringBuffer takostr = new StringBuffer( "蛸はどうした?" ); takostr.setCharAt( 0, '鮪' ); // "鮪はどうした?" に変更されます System.out.println( ""+takostr );
replace( 先頭の位置, 終了直後の位置, 取り替える文字列 )実際の例を見てみます。次の例は、「さんま」を「たらこ」に取り替えています。
StringBuffer sentence = new StringBuffer( "目黒のさんまが食べたいなあ" ); sentence.replace( 3, 6, " たらこ"); // "目黒のたらこがたべたいなあ" printLine( ""+sentence ); // あるいは、printLine( new String( sentence) );
delete( 先頭の位置, 終了直後の位置 )
insert( 先頭の位置, 挿入する文字列 )
append( 追加する文字列 );
StringBuffer sentence = new StringBuffer( "This is a simple example of a simple replace testing in a program." );
for ( int scan=0; scan < sentence.length; scan++ ) {
scan = sentence.indexOf( "a ", scan )
if ( scan < 0 ) { break; }
sentence.delete( scan, scan+2 );
sentence.insert( scan, "the " );
}
printLine( ""+sentence ); // あるいは、printLine( new String( sentence) );
public class StringToWord {
public static void main( String [ ] args ) {
String source = "Can you tell me how to get to the airport";
String wordList [ ] = new String[ 20 ];
// 単語リストに分解する
int wordcount = 0;
int start, end;
for ( start=0; startfor ( end = start; end < source.length( ) ; end++ ) {
if ( source.charAt( end ) == 32 ) { break; }
}
wordList[ wordcount ] = source.substring( start, end );
wordcount ++ ;
}
// 分解した単語リストをすべて表示する
for ( int i = 0 ; i < wordcount ; i++ ) {
System.out.println( wordList[ i ] );
}
}
}
一つの単語を取り出すには、startの位置から始めて、endの位置に空白があるかどう内側の繰返しで走査しています。なければ、endの位置を後ろに一つずつずらしていきます。空白が見つかったら、内側の繰返しを抜け出します。そして、startの位置からendの位置の手前までの部分的な文字列をsubstringメソッドで抜き出して、それをwordListに追加しています。外側の繰返しで、次のstart位置はendの次の位置にして、同じことを行なうようにします。最終的に、文字列の最後までこれを繰り返すと単語リストに分解することができます。次の図は、tellという単語を取り出すときのstartとendの値を示しています。
図 tellを取り出すときのstartとend
78, 343, 33, 22 90, 78, 220, 221 10, 100, 150, 200 :このような1行に複数の情報が、何らかの区切り用の文字で区切られて保存されている場合には、java.utilパッケージの中に便利なStringTokenizerクラスが用意されています。これは、文字列を区切りの文字列で分解するものです。分解された文字列は、トークン(Token)と呼ばれています。次のようなコンストラクタとメソッドが利用できます。
new StringTokenizer( 文字列, 区切りの文字列 ) // 文字列を区切りの文字列で分解しますなお、StringTokenizerは、java.utilパッケージなので、プログラミングの先頭に次のような一文をいれておく必要があります。
String nextToken( ) // 次のトークンを返します
int countTokens( ) // トークンがいくつあるか返します
boolean hasMoreTokens( ) // 次のトークンがあるかどうか返します
import java.util.*;なお、区切りの文字列に複数の文字を記述することもできます。各文字をすべて区切りとして認識してくれます。たとえば、次のようなプログラムの断片を記述することができます。これは、スペースで区切られた文字列をトークンに分解して表示するものです。
StringTokenizer tokens = new StringTokenizer( "This is a sample message", " " );
while ( tokens.hasMoreTokens( ) ) {
System.out.println( "Token is " + tokens.nextToken( ) );
}
結果は次のように表示されます。
This is a sample message
import java.util.*;
public class TokenTester {
public static void main( String [ ] args ) {
TokenTester myself = new TokenTester( );
String [ ] result = myself.decompose( "Hello, my matured example!" );
for ( int i = 0; i < result.length ; i++ ) {
System.out.println( "word: " + result[ i ] );
}
}
String [ ] decompose( String source ) { // 文字列の配列を返すメソッド
StringTokenizer tokens = new StringTokenizer( source, " " );
String [ ] wordlist = new String[ tokens.countTokens( ) ];
for ( int i = 0; i < wordlist.length ; i++ ) {
wordlist[ i ] = tokens.nextToken( );
}
return wordlist;
}
}
| <<Standard Java | ⋏ Return to Columns | >>Graphics and Curves |